




Convert YouTube videos to engaging shorts effortlessly. Elevate views, subscribers, and channel growth.

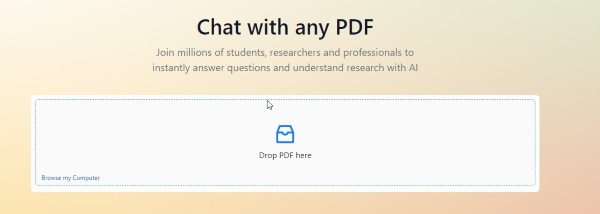
BrainyPDF’s functionality is limited in viewing all pages of a PDF due to its ability to focus on only a few relevant paragraphs per question. The tool clarifies that its scope is restricted to the most pertinent content, often citing this constraint when it can’t analyze the entire document.
The process behind BrainyPDF involves creating a semantic index encompassing all PDF paragraphs during the analysis stage. When responding to queries, the tool extracts the most suitable paragraphs and employs OpenAI’s ChatGPT API to generate answers, ensuring informative responses.
However, BrainyPDF faces limitations in handling images and tables within PDFs. It currently lacks the capability to interpret images, including scanned text images, while it can process textual content in tables. Nonetheless, it might encounter challenges in accurately correlating specific rows and columns in tables.
While BrainyPDF currently relies on GPT 3.5—identical to ChatGPT—plans are underway to integrate GPT-4. However, access to GPT-4’s capabilities under the free plan might be limited due to cost considerations. Despite these limitations, BrainyPDF provides valuable PDF analysis and answers, offering a useful tool for extracting insights from textual content.
Advt:
Copywrite© 2023 WebGuide

Sign in to your account